RAG遇见LLM:检索增强型大语言模型综述
📖 综述概览
本文系统性综述了**检索增强型大语言模型(RA-LLMs)**的研究进展,涵盖架构设计、训练策略、应用场景三大核心维度,探讨当前挑战与未来研究方向。
🗺️ 文章导航
本文从以下维度全面解析RAG技术:
- 🧭 引言与背景 - RAG的提出动机与研究意义
- 🧠 背景知识 - LLMs基础与Prompt Learning
- 🔍 核心组成 - 检索、生成、增强三大模块
- 🏋️ 训练策略 - 从无训练到联合训练
- 🧪 应用场景 - NLP应用到垂直领域
- 🔮 未来方向 - 可信性、多模态等前沿挑战
🧭 一、引言(Introduction)
🎯 背景介绍
检索技术(Retrieval)
- ✅ 数据挖掘的基础手段
- ✅ 广泛应用于搜索、问答、推荐等任务
大语言模型(LLMs)的挑战
- ❌ 幻觉(Hallucination) - 生成不准确或虚构的信息
- ⏰ 知识过时 - 训练数据无法涵盖最新知识
- 🔒 领域适应性差 - 通用模型在专业领域表现受限
💡 RAG的提出动机
核心思想
将外部知识库与大语言模型结合,通过**检索增强生成(RAG)**技术:
- 📈 提升模型回答的准确性
- ⏱️ 增强知识的时效性
- 🎯 改善领域任务的适应性
🎯 文章目标
| 维度 | 内容 |
|---|---|
| 📊 架构设计 | 系统梳理检索器、生成器、增强策略 |
| 🏋️ 训练策略 | 分析无训练、独立、顺序、联合训练方法 |
| 🧪 应用场景 | 覆盖NLP、推荐、代码生成、科学发现等领域 |
| 🔮 未来方向 | 探讨可信性、多模态、多语言等前沿挑战 |
🧠 二、背景知识(Background)
2.1 大语言模型(LLMs)
📋 模型分类
| 架构类型 | 代表模型 | 适用场景 |
|---|---|---|
| Encoder-only | BERT | 理解任务 |
| Decoder-only | GPT系列 | 生成任务 |
| Encoder-Decoder | T5, BART | 序列转换任务 |
⚖️ 优势与局限
✅ 优势
- 🚀 强大的语言理解与生成能力
- 🎨 零样本/少样本学习能力
- 🔄 迁移学习能力
❌ 局限性
- 💭 幻觉问题 - 可能生成虚假信息
- 📅 知识更新困难 - 训练后知识固化
- 🏥 领域适应性差 - 垂直领域表现不佳
- 💰 计算成本高 - 推理和训练资源需求大
2.2 Prompt学习与上下文学习
🔧 Prompt Engineering
技术要点
- 📝 手工模板(Cloze / Prefix Prompt)
- 🧩 软提示(Soft Prompt Tuning)
- 🎯 自动提示学习
代表方法
- Prefix-Tuning
- P-tuning v1/v2
🎓 In-Context Learning (ICL)
ICL特点
- ✅ 通过示例让模型学习任务模式
- ✅ 无需微调参数
- ⚠️ 对示例质量高度敏感
- ⚠️ 缺乏最新/专业领域知识 → 引入RAG
🔍 三、RA-LLMs的核心组成
3.1 检索模块(Retrieval)
3.1.1 检索器类型
🔹 稀疏检索(Sparse Retrieval)
代表方法:BM25、TF-IDF
| 特点 | 说明 |
|---|---|
| ⚙️ 原理 | 基于词频和倒排索引 |
| ✅ 优点 | 无需训练、部署简单、高效 |
| ❌ 缺点 | 无法捕捉语义相似性 |
🔹 稠密检索(Dense Retrieval)
代表方法:DPR、Contriever、Spider
| 特点 | 说明 |
|---|---|
| ⚙️ 原理 | 向量编码 + 语义相似度 |
| ✅ 优点 | 语义匹配、可训练优化 |
| 🏗️ 结构 | 双编码器/单编码器 |
3.1.2 检索粒度
| 粒度类型 | 优点 | 缺点 | 典型场景 |
|---|---|---|---|
| 📄 文档级 | 信息完整 | 冗余多、噪声大 | 长文本理解 |
| 📝 段落级 ⭐ | 信息紧凑、效果好 | 可能截断上下文 | 主流选择 |
| 🔤 Token级 | 精细控制 | 存储成本高 | 稀有模式检索 |
| 🏷️ 实体级 | 结构化知识 | 构建复杂 | 知识图谱应用 |
3.1.3 检索前后增强
🔧 Pre-Retrieval(检索前增强)
| 技术 | 描述 | 优势 |
|---|---|---|
| Query2doc | LLM生成伪文档扩展查询 | 丰富查询语义 |
| HyDE | 生成假设文档进行向量检索 | 跨越词汇鸿沟 |
| Query Rewrite | 重写查询以匹配知识库 | 提升召回率 |
| Query Augmentation | 结合初步输出再检索 | 迭代优化 |
🔧 Post-Retrieval(检索后增强)
| 技术 | 描述 | 优势 |
|---|---|---|
| PRCA | 强化学习过滤/重排上下文 | 提升相关性 |
| Re2G | 多路检索结果重排序融合 | 融合多源信息 |
| RECOMP | 压缩检索文档为摘要 | 减少token消耗 |
| BlendFilter | 查询生成+知识过滤 | 降低噪声 |
3.1.4 外部知识源
知识库类型
| 类型 | 特点 | 代表 | 优势 | 挑战 |
|---|---|---|---|---|
| 📚 Wikipedia | 结构化事实知识 | 通用百科 | 覆盖广泛 | 更新滞后 |
| 🔍 搜索引擎 | 实时动态知识 | Bing/Google | 时效性强 | 噪声较多 |
| 🏥 领域数据库 | 专业垂直知识 | 医疗文献、API文档 | 专业性强 | 构建成本高 |
| 🗄️ 键值存储 | 向量数据库 | FAISS, Milvus | 检索高效 | 需维护索引 |
3.2 生成模块(Generation)
3.2.1 白盒生成器(Parameter-Accessible)
✅ 特点
- 可访问模型参数
- 支持微调训练
- 可定制融合策略
🏗️ 融合方式
| 模型 | 结构 | 融合方式 | 特点 |
|---|---|---|---|
| FiD | Encoder-Decoder | 输入层:多文档独立编码 | 处理多文档效果好 |
| RETRO | Encoder-Decoder | 中间层:Chunked Cross-Attention | 深度融合检索信息 |
| EAE | Transformer | 实体记忆层 | 结构化知识融合 |
| RAG | BART | 输入层:检索文档拼接 | 经典两阶段框架 |
3.2.2 黑盒生成器(Parameter-Inaccessible)
黑盒模型约束
- ❌ 无法访问模型参数
- ❌ 无法进行微调
- ✅ 仅能通过Prompt Engineering利用检索结果
🔧 增强策略
| 技术 | 描述 | 适用模型 |
|---|---|---|
| Prompt Retrieval | 检索最优prompt示例 | GPT-3/4 |
| Context Compression | 压缩检索文档为摘要 | Claude, GPT |
| In-Context Integration | 拼接检索文档到prompt | 通用黑盒LLM |
3.3 增强策略(Augmentation)
融合层级对比
| 融合层级 | 白盒 | 黑盒 | 技术代表 | 优缺点 |
|---|---|---|---|---|
| 🔼 输入层 | ✅ | ✅ | 拼接文档、Prompt增强 | ✅简单 ❌长度受限 |
| 🔁 中间层 | ✅ | ❌ | Cross-Attention、Memory Layer | ✅深度融合 ❌需访问参数 |
| 🔽 输出层 | ✅ | ✅ | 分布插值、答案修正 | ✅灵活 ❌推理复杂 |
3.4 检索时机与频率
🎯 检索策略
| 维度 | 方法 | 代表系统 |
|---|---|---|
| 是否检索 | 自反思判断 | Self-RAG, SKR |
| 检索频率 | 一次检索 | REALM |
| 检索频率 | 每n个token | RETRO |
| 检索频率 | 每个token | kNN-LM |
🏋️ 四、训练策略(Training Strategies)
训练方法总览
| 策略类型 | 特点 | 优点 | 缺点 | 代表方法 |
|---|---|---|---|---|
| 🚫 Training-free | 无需训练 | 高效、适配黑盒模型 | 性能受限 | In-Context RALM |
| 🔀 Independent | 独立训练 | 模块化、灵活 | 未对齐、次优 | DPR + T5 |
| ⏩ Sequential | 顺序训练 | 有监督信号、性能较好 | 训练复杂度中等 | RETRO, RA-DIT |
| 🔗 Joint | 端到端联合训练 | 完全对齐、性能最佳 | 资源消耗大 | RAG, REALM |
4.1 Training-free方法
核心思想
在推理时将检索结果插入Prompt或调整生成分布,无需微调模型
🔧 技术方式
- Prompt Engineering
- 检索引导生成
- 选择性检索
📚 代表文章
- In-Context RALM - 上下文拼接式检索
- IRCoT - 交错检索与CoT推理
- SKR - 知识充足性判断
- GENREAD - 生成-检索-阅读流程
4.2 Independent Training(独立训练)
⚠️ 优缺点分析
- ✅ 模块化设计、易于维护
- ✅ 可独立优化各组件
- ❌ 检索与生成未对齐
- ❌ 性能可能次优
📚 代表方法
- DPR - 双编码器对比学习
- CoG - 独立优化检索与生成
4.3 Sequential Training(顺序训练)
🔄 Retriever First
Step 1: 训练检索器(BERT/DPR)
↓
Step 2: 冻结检索器
↓
Step 3: 训练生成器(T5/BART)
🔄 LLM First
Step 1: 训练/微调LLM
↓
Step 2: 冻结LLM
↓
Step 3: 用LLM注意力训练检索器
📚 代表文章
- RETRO - Chunked Cross-Attention融合
- DKRR - 生成器注意力蒸馏
- RA-DIT - 对齐LLM知识需求
- UPRISE - 检索器微调
4.4 Joint Training(联合训练)
端到端优化
检索器与生成器同时训练,通过统一损失函数优化
🔧 技术要点
- 负对数似然损失统一优化
- 异步索引更新策略
- 检索器输出文档概率
⚖️ 优缺点
| ✅ 优点 | ❌ 缺点 |
|---|---|
| 检索与生成完全对齐 | 训练复杂度高 |
| 性能最佳 | 资源消耗大 |
| 端到端可微 | 需要大规模计算 |
📚 代表文章
- RAG - 经典两阶段框架
- REALM - 预训练阶段引入检索
- Atlas - 少样本场景联合训练
🧪 五、应用场景(Applications)
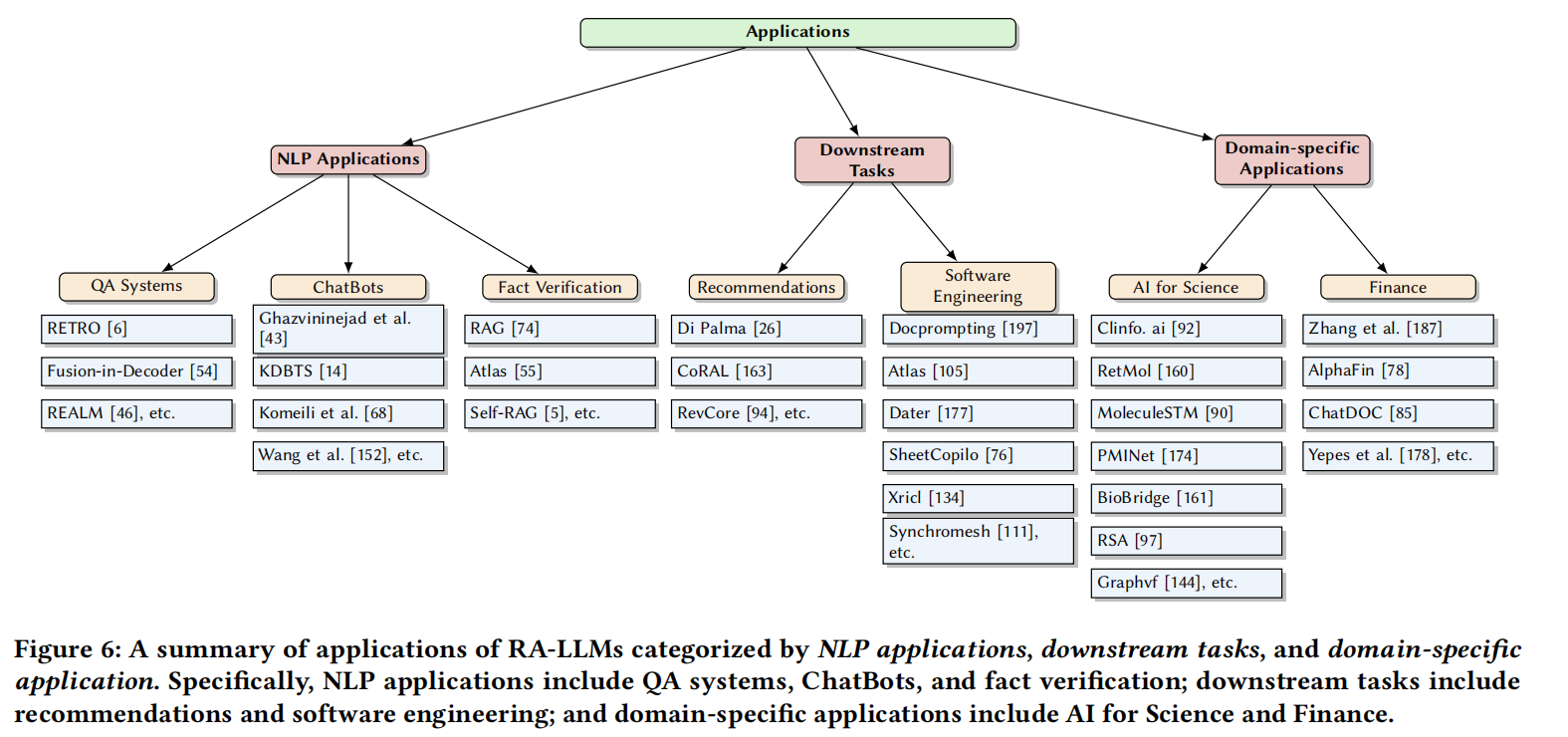
5.1 NLP基础应用
5.1.1 问答系统(QA Systems)
❓ 核心挑战
- LLM缺乏最新知识
- 领域知识不足
- 答案缺乏可验证性
📚 代表系统
| 系统 | 技术特点 | 优势 |
|---|---|---|
| REALM | 预训练阶段引入检索器 | 端到端优化 |
| FiD | 每篇文档独立编码融合 | 多文档处理好 |
| Atlas | Few-shot QA联合训练 | 少样本场景强 |
5.1.2 对话系统(ChatBot)
对话系统的RAG应用
- 动态检索外部知识(维基、互联网)
- 增强多轮对话的知识连贯性
- 提供可引用的信息来源
5.1.3 事实验证(Fact Verification)
🔍 Self-RAG自反思机制
- 判断是否需要检索
- 评估检索证据可靠性
- 生成带引用的答案
5.2 下游任务应用
5.2.1 推荐系统
| 系统 | 技术方案 | 创新点 |
|---|---|---|
| RevCore | 检索用户评论增强对话推荐 | 提升推荐解释性 |
| CoRAL | 强化学习对齐协同信号与语义 | 跨模态信息融合 |
5.2.2 软件工程
| 任务 | 技术方案 | 代表系统 |
|---|---|---|
| 代码生成 | 检索相似代码/API文档 | DocPrompting |
| Text-to-SQL | 结构化检索增强 | Synchromesh |
| 表格操作 | 检索历史命令 | SheetCopilot |
5.3 垂直领域应用
5.3.1 AI for Science
| 领域 | 系统 | 技术特点 |
|---|---|---|
| 🧬 分子发现 | RetMol | 检索分子片段辅助生成 |
| 🧬 分子发现 | MoleculeSTM | 分子-文本跨模态检索 |
| 🧪 蛋白质 | RSA | 检索相似序列增强表示 |
| 📚 医学文献 | Clinfo.ai | 回答临床问题 |
5.3.2 金融分析
| 系统 | 应用场景 | 技术方案 |
|---|---|---|
| AlphaFin | 股票分析 | 检索新闻+研报构建推理链 |
| ChatDOC | 文档问答 | PDF结构识别+检索增强 |
| FinGPT | 金融问答 | 多源信息融合 |
🔮 六、未来挑战与研究方向
挑战概览
| 🎯 方向 | ❓ 关键问题 | 💡 潜在解决方案 |
|---|---|---|
| 🛡️ 可信RA-LLMs | 鲁棒性、公平性、可解释性、隐私保护 | 对抗训练、可解释性增强、差分隐私 |
| 🌍 多语言RA-LLMs | 跨语言知识检索与生成 | 多语言知识库、跨语言对齐 |
| 🎨 多模态RA-LLMs | 融合图像、音频、视频信息 | 多模态编码器、跨模态检索 |
| ✅ 知识质量控制 | 错误、过时、偏见知识的影响 | 知识验证、时效性检测、去偏见 |
6.1 可信RA-LLMs
可信性挑战
🛡️ 鲁棒性
- 对抗样本攻击
- 检索结果噪声
⚖️ 公平性
- 检索偏见
- 生成偏见
🔍 可解释性
- 检索决策透明度
- 生成过程可追溯
🔐 隐私保护
- 检索历史隐私
- 用户数据安全
6.2 多语言与多模态
🌍 多语言挑战
- 跨语言检索对齐
- 低资源语言支持
- 知识迁移学习
🎨 多模态融合
- 图像+文本检索
- 音频增强生成
- 视频内容理解
6.3 知识质量控制
| 问题类型 | 影响 | 解决方案 |
|---|---|---|
| ❌ 错误知识 | 生成不准确答案 | 知识验证、多源对比 |
| ⏰ 过时知识 | 信息时效性差 | 时间戳检测、动态更新 |
| 🎭 偏见知识 | 不公平输出 | 去偏见算法、多样性采样 |
📊 附录:核心技术汇总
RAG Framework演进
| 方法 | 年份 | 引用量 | 核心特点 |
|---|---|---|---|
| kNN-LM | 2019 | 500-1000 | 首个token级RAG,输出层插值 |
| REALM | 2020 | >1000 | 预训练阶段引入检索 |
| RAG | 2020 | >1000 | 经典两阶段:DPR+BART |
| FiD | 2021 | 500-1000 | 多文档独立编码融合 |
| RETRO | 2021 | 500-1000 | 中间层Chunked Cross-Attention |
| Self-RAG | 2023 | 50-100 | 自反思token控制检索 |
📚 参考资料
延伸阅读
本综述涵盖了200+篇相关文献,建议按以下顺序深入学习:
- 基础框架: REALM, RAG, FiD
- 进阶方法: RETRO, Self-RAG, Atlas
- 应用案例: DocPrompting, AlphaFin, RetMol
关键词: RAG, 检索增强生成, 大语言模型, LLM, 知识检索, 向量数据库, Prompt Learning, In-Context Learning
最后更新: 2025-10-25